Abstract
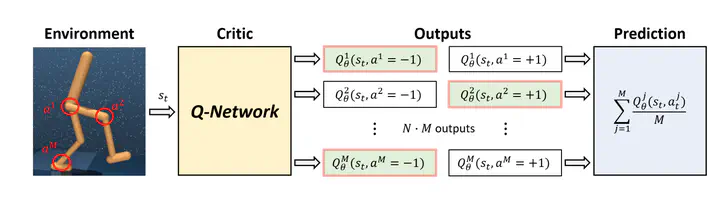
While there has been substantial success in applying actor-critic methods to continuous control, simpler critic-only methods such as Q-learning often remain intractable in the associated high-dimensional action spaces. However, most actor-critic methods come at the cost of added complexity: heuristics for stabilization, compute requirements as well as wider hyperparameter search spaces. We show that these issues can be largely alleviated via Q-learning by combining action discretization with value decomposition, framing single-agent control as cooperative multi-agent reinforcement learning (MARL). With bang-bang actions, performance of this critic-only approach matches state-of-the-art continuous actor-critic methods when learning from features or pixels. We extend classical bandit examples from cooperative MARL to provide intuition for how decoupled critics leverage state information to coordinate joint optimization, and demonstrate surprisingly strong performance across a wide variety of continuous control tasks.